프리미티브 타입의 종류와 값의 범위
자바에서는 기본형(원시) 타입이라고 불리는 프리미티브(Primitive) 총 8가지 타입이 존재한다. (String의 경우 기본타입이 아님)
(JVM Runtime Data Area 영역중 Stack 영역에 값이 저장된다)
원시 타입의 종류)

참조타입
기본타입을 제외한 나머지 모든 타입을 참조타입(new를 통해 객체를 생성하여 데이터가 생성된 주소를 가리킴)이라고 한다.
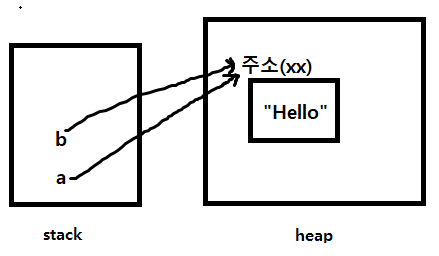
String a = "Hello";
String b = "Hello";String(문자열)은 new를 생성하지 않고 쓰지만 내부적으로는 스택에 있는 a와b의 변수가 heap영역의 "Hello"라는 데이터가 있는 주소를 가리키고 있다.(만약 문자열 리터럴이 동일하다면 a와b의 변수는 같은 주소를 참조하게 된다)
String c = new String("Hello");
String d = new String("Hello");new를 통해 객체를 생성한 경우에는 서로다른 인스턴스(객체)가 만들어지기 때문에 참조하는 주소값이 다르다.

리터럴
상수(값을 한번 저장하면 저장된 값을 변경할수 없는 저장공간)와 달리 리터럴은 값 그 자체를 의미한다.
final int YEAR = 2021;
// YEAR -> 상수(값이 저장되는 공간이지만 한번 저장되면 변경불가능) 상수라는 의미의 final 붙여줌
// 2021 -> 리터럴(값 그자체)
int year = 2021;
// int -> 데이터 타입
// year -> 변수(값을 저장하기 위한 공간)
// 2021 -> 리터럴
변수에 타입이 있는 것처럼 리터럴에도 타입이 있음 정수형과 실수형의 경우에는 여러 타입이 존재하므로,
리터럴에 접미사를 붙여서 타입을 구분한다. byte와 short타입의 리터럴은 존재하지 않으며 int타입의 리터럴을 사용함
// 정수형
int a = 100; // 접미사가 없으므로 int타입의 리터럴
short b = 100;
byte c = 100;
long d = 10000000L; // long 타입의 리터럴은 접미사 L 또는 l을 붙임
// 실수형
float pi = 3.14f; // 접미사 f 또는 F를 붙여서 float 타입의 리터럴을 나타냄
double rate = 5.123d; // 접미사 d 또는 D를 붙여서 double 타입의 리터럴을 나타냄
double rate1 = 5.123; // 접미사 생략가능(실수형의 기본 리터럴 double) 정수형에서는 int가 기본 자료형이기 때문에 정수형 타입을 선언한 다음 접미사가 없는 값을 적으면 int리터럴임을 나타낸다.
실수형에서는 double이 기본 자료형이기 때문에 float타입을 선언한 다음 float 리터럴 값을 넣기 위해서는 접미사 f 또는 F를 붙여줘야 된다.
10진수 이외에도 2,8,16진수로 표현된 리터럴을 변수에 저장할 수 있다.
int a = 0b10; // 접두사(0b) -> 2진수
int b = 010; // 접두사(0) -> 8진수
int c = 10; // 접두사 X -> 10진수
int d = 0x10; // 접두사(0x) -> 16진수
System.out.println("2진수:"+a); // 2진수(10) -> 십진수(2)
System.out.println("8진수:"+b); // 8진수(10) -> 십진수(8)
System.out.println("10진수:"+c); // 10진수(10) -> 십진수(10)
System.out.println("16진수:"+d); // 16진수(10) -> 십진수(16)
실수타입이 정수타입보다 값의 범위가 큰 이유는? (***)
컴퓨터는 0과1로 이루어진 기계어를 사용해 해당 데이터를 이진법으로 저장한다.
십진수 숫자8을 컴퓨터는 1000 이라는 이진수 형태로 표현을 한다. 그러면 0.0005와 같은 실수를 컴퓨터는 어떻게 표현(저장)을 할까? 그리고 실수의 정밀도는 어느정도까지 표현이 가능할까?
실수를 표현하는 2가지 방식이 있다.
1.고정 소수점(Fixed Point)
16비트체계를 쓴다고 가정하였을때 1비트(부호비트) + 7비트(정수부) + 8비트(소수부)

위 그림은 십진수인 7.625 실수형태를 이진수로 바꾸어 저장한 형태이다.
맨 앞자리는 부호비트(0이면 양수 1이면 음수)이고 특정 위치에 소수점을 고정해놓고 소수점 앞자리에는 실수의 정수부(7->111) 뒷자리에는 실수의 소수부(625->101)를 표현한다.
소수점의 위치가 정해져 있으므로 표현가능한 실수의 범위와 정밀도가 낮을 수 밖에 없다.
2.부동 소수점(Floating Point) (****)
고정 소수점이 가지고 있는 실수의 범위와 정밀도 문제를 해결하기 위해서 소수점의 위치가 고정되어 있지 않고 유동적인 부동소수점이 등장하였다.
부동소수점 방식으로 실수를 저장하는데 32bit,64bit가 사용된다.(아래 그림은 32bit 기준으로 설명)
자바에서 float - 32bit(4byte) , double - 64bit(8byte) 해당한다고 볼 수 있다.

7.625(십진수)를 111.101(이진수)로 변환한 결과에서 끝나는 것이 아니라 정규화라는 작업을 거치게 된다.
111.101(이진수) -> 1.11101 * 2^2(2의제곱승) 으로 정규화 작업이 끝나면 부동소수점 방식으로 해당 수를 저장하게 된다.(자세한 계산은 복잡하므로 생략하겠다 추후에 더 깊게 뜯어보자)

근데 왜 int(4byte) 와 float(4byte)는 똑같은 메모리 공간을 가지고 있는데 표현할 수 있는 범위의 차이가 큰것일까?
int의 경우 부호비트인 1bit를 제외한 31bit로 수(양수+음수)의 표현이 가능한 반면에
float의 경우에 부호비트 1bit를 제외하고 31bit를 쪼개서 지수부랑 가수부로 나눠서 실수를 표현하기 때문에
int 보다 더 큰 범위의 표현이 가능하지만 저장하려던 값과 실제 저장된 값이 오차가 발생 할 수 있다.
float 경우 6자리 정밀도(소수점 아래 6자리의 정밀도)를 갖고,
double의 경우 15자리 정밀도(소수점 아래 15자리의 정밀도)를 갖기 때문에 해당 범위를 벗어나게 되면 오차가 발생하게 된다.
float 형의 실수 계산)
// float 형태로 실수 0.12을 7번 더한 경우
float a = 0.12f;
for(int i=0;i<7;i++) {
a += 0.12f;
System.out.println(a);
}
첫번째 0.12 + 0.12 더했을때 0.24로 표현이되지만 그다음 0.24 + 0.12를 더했을때 컴퓨터가 float형태의 정밀도를 소수점 아래 6자리까지 처리가 가능하므로 0.3599998 이라는 오차가 발생하게 된다.
(0.24 + 0.12 -> 0.36으로 인간은 한눈에 계산 할 수 있지만 사실 컴퓨터가 계산하는 실수는 오차가 발생 할 수 있다.)
double 형의 실수 계산)
// double 형태로 실수 0.2을 7번 더한 경우
double b = 0.12;
for(int i=0;i<7;i++) {
b += 0.12;
System.out.println(b);
}
double 형의 경우 float보다 정확한 실수의 정밀도를 표현 할 수 있기 때문에 오차범위가 발생하지 않은것을 볼수 있지만... 소수점 아래 15자리 까지 정밀도를 갖기 때문에 더 큰 실수의 계산을 할 경우에 오차가 발생하는 것을 볼 수 있다.
// double 형태로 실수 0.1234을 7번 더한 경우
double b = 0.1234;
for(int i=0;i<7;i++) {
b += 0.1234;
System.out.println(b);
}
실수를 저장 할 수 있는 가장 큰 타입인 double형도 소수점의 정밀도에 한계가 있기 때문에 정밀도를 좀더 큰 범위까지 저장할 수 있게끔 자바에서 BigDecimal 이라는 것을 사용한다.
BigDecimal 타입으로 실수를 계산한 방법)
BigDecimal a1 = new BigDecimal("0.1234");
for(int i=0;i<7;i++) {
BigDecimal a2 = new BigDecimal("0.1234");
a1 = a1.add(a2);
System.out.println(a1);
}
정적타입 VS 동적타입
정적타입)
정적타입은 컴파일시 변수의 타입이 결정되는 언어(Java,C,C++)를 말함
변수에 들어갈 리터럴 값의 형태에 따라서 직접 변수의 타입을 명시해줘야 한다.
int a = 100;
String b = "Hello"Java의 경우 JDK 10 이상부터 var 라는 타입추론으로 타입명시를 안해도 초기의 변수에 할당되는 리터럴 값에 따라서 타입이 내부적으로 명시된다. (var라는 타입추론도 컴파일시 내부적으로 타입이 명시되서 컴파일됨)
var a = 12; // 컴파일시 내부적으로 int 타입으로 선언이됨
a = "hello"; // int 타입이므로 문자열인 "hello" 할당 불가능
var b = "hello"; // String 타입 변수
b = 12; // int 리터럴 12 할당 불가능
// 변수 선언후 해당 변수에 값 할당이 불가능 (초기화 작업이 무조건 진행되야됨)
var a; // 타입 추론이 불가능
a = 10; 장점 : 타입에러로 인한 문제점을 초기(컴파일 과정에서)에 발견가능
단점 : 코드 작성시 일일히 리터럴값에 맞춰서 타입을 결정해 줘야됨
동적타입)
컴파일시 타입이 결정되는 것이 아니라 런타임시 변수의 타입이 결정됨 (파이썬,자바스크립트 ..등등)
var a = 12; // 12라는 수를 넣으면 정수타입이됨
a = "hello"; // 정수타입인 a에 "hello"라는 문자열을 넣게되면 문자열 타입으로 바뀜 장점 : 타입을 명시하지 않아도 되기때문에 정적타입 언어보다 코드를 빠르게 작성 가능
단점 : 런타임 도중 변수에 예상치 못한 타입이 들어와서 타입에러가 발생할 수 있음(이런 경우는 언제일까??)
동적타입으로 작성한 언어로 타입에러가 발생할 수 있다는 것이 와닫지 않음
(어떤 경우에 타입에러가 발생하는 거지??)
추가적인 것들)
자바 8이상부터는 _(언더바)를 표기해서 정수를 표현할 수 있음
int a = 1_000_000;
System.out.print(a); // 1000000 출력됨
'프로그래밍 언어' 카테고리의 다른 글
| 자바 스터디(예외) (0) | 2021.02.24 |
|---|---|
| 디버거 사용하기 (0) | 2021.02.21 |
| 자바 1주차 스터디 (0) | 2021.02.16 |
| 다형성 (0) | 2021.02.12 |
| 추상클래스 , 인터페이스 개념 (0) | 2021.01.28 |

